
Una de las características no tan visibles, pero muy ventajosas de las arquitecturas clean, es que nos permiten aplazar las decisiones relativas a los detalles de implementación. Es decir, la teoría dice que antes de empezar una aplicación, no deberíamos tomar decisiones precipitadas de cosas como:
- Qué sistema de base de datos utilizar
- Desarrollar un monolito o microservicios
- Elegir un framework de inyección de dependencias
- Almacenar ficheros en local o en la nube
- Elegir un proveedor de envío de notificaciones por e-mail
Ventajas de aplazar las decisiones
Las arquitecturas de software buscan optimizar la manera en la que desarrollamos e introducimos cambios en las aplicaciones. Para que una arquitectura sea flexible, hay que mantener abiertas las opciones que podamos, tanto tiempo como nos sea posible. Las opciones que podemos mantener abiertas son las referentes a los detalles, entendiendo por detalles las implementaciones técnicas de los componentes de la aplicación que no pertenecen a las reglas de negocio.
Mantener abiertas las opciones retrasando estas decisiones nos permite darle mayor relevancia a lo que es más importante en una aplicación: las reglas de negocio, donde realmente está el valor.
Esto nos permite enfocar el desarrollo centrándonos en las reglas de negocio y sus necesidades, y no al revés, ya que decidir de antemano los detalles de implementación puede provocar la tentación de “acomodar” el modelado y funcionalidad de las reglas de negocio para que encajen mejor en el sistema externo al dominio.
Además, aplazar estas decisiones nos permite también tener más información sobre las necesidades reales de la aplicación, y tomar mejores decisiones respaldadas por requisitos reales que han surgido, y no únicamente los estimados antes de comenzar el desarrollo. Todos sabemos lo que puede cambiar una aplicación durante su desarrollo, ya sea debido a temas inesperados que no se han tenido en cuenta, o por cambios de requisitos de negocio por parte del cliente. Esto es útil especialmente si seguimos metodologías ágiles, que favorecen las iteraciones y el pivotaje funcional según se avanza y se va obteniendo *feedback *de las partes implicadas.
También nos permite realizar experimentos, de manera que si implementamos un componente podemos probar su funcionamiento, y si no nos convence, cambiarlo por otro.
También puede beneficiar a los tests unitarios, dado que de la misma manera, al aplazar las decisiones los tests están menos expuestos a inferencias externas al negocio testeado.
Por último, aplazar las decisiones nos evita enfrentarnos a problemas derivados de los detalles de implementación. Por ejemplo, si desde el primer momento estamos acoplados a un sistema de base de datos, tendremos que gastar energía para enfrentarnos a los dolores de cabeza que esos sistemas pueden darnos: cambios en el esquema, problemas de conectividad, optimización de queries, lentitud en los tests, etc.
Evitando las decisiones prematuras gracias a Clean Architecture
En este contexto, una decisión prematura es aquella que se toma sin que haya necesidad para los requisitos de negocio que estamos desarrollando. Como hemos dicho antes, esas decisiones sobre los *detalles *abarcan la elección de bases de datos, frameworks, librerías, etc. Una buena arquitectura no debería depender de ninguna de esas decisiones.
Lógicamente, llegará un punto en el que no se podrá aplazar más una decisión, pero cuanto más tarde llegues a ese punto, más información tendremos para tomar una decisión adecuada.
Incluso si la decisión ya viene dada por causas externas al desarrollador, como por ejemplo si tu empresa es partner de algún producto y es obligatorio su uso, conviene actuar como si esa decisión no estuviera tomada aún.
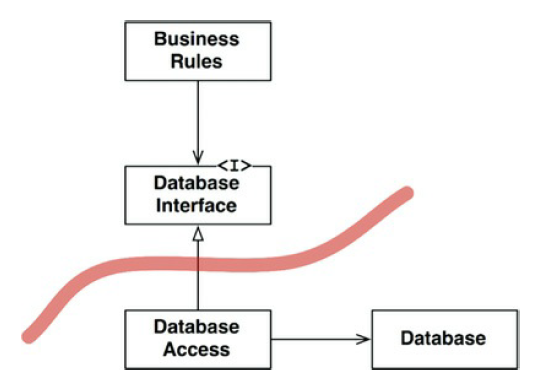
Clean Architecture permite aplazar decisiones gracias a su división de aspectos mediante boundaries, que son límites “fuertes” que separan las capas. La implementación típica de un boundary es el uso conjunto de interfaces e inversión de dependencias. Lo necesario para las reglas de negocio de la aplicación queda definido en una interfaz del dominio, y el componente (detalle) debe cumplir ese contrato.
En el caso típico de la persistencia de datos, el negocio no debe preocuparse de cómo se ejecutan las queries, todo lo que necesita es un conjunto de funciones para obtener o almacenar datos, que quedan definidas en el propio negocio en una interfaz.
¿Es realmente útil todo esto?
En ocasiones he visto opiniones críticas respecto a si aplazar decisiones técnicas es realmente útil. Bajo ese prisma del pragmatismo, hay gente que piensa que no lo necesita, ya que tiene muy claro que por ejemplo va a utilizar un MySQL para la persistencia de datos, porque todas las webs que ha hecho así lo han requerido. ¿Pero fue antes el huevo o la gallina? Puede que siempre use MySQL porque es la costumbre y no se plantea otra opción en ningún caso, y su arquitectura le impide salir de esa falsa zona de confort.
El propio Uncle Bob en su libro Clean Architecture, expone un caso de una aplicación en la que comenzaron implementando un sistema muy rudimentario de persistencia de datos, primero en memoria y más adelante en ficheros de texto plano, con la idea de centrarse en el desarrollo de lo importante (el dominio). Siempre tuvieron en mente implementar una base de datos más potente como MySQL, pero eso nunca llego a ser necesario, y el sistema de persistencia en ficheros de texto plano se quedó como el definitivo, porque la propia aplicación no ha expresado la necesidad de algo más complejo.
Otro argumento que provoca escepticismo en los críticos del aplazamiento de decisiones es cuando se les plantea de manera vaga: “al hacerlo así, si algún día queremos podemos pasar de un sistema SQL a un NoSQL, o cambiar de SQLServer a Oracle”. Obviamente, estos casos son muy extraños, y no es normal tener que cambiar de motor de persistencia de una aplicación. Sin embargo, aunque el sistema de base de datos es uno de los grandes protagonistas en cuanto a *detalles *de implementación técnica, hay muchos otros componentes en los que un cambio en caliente de proveedor no es para nada descabellado. Por ejemplo, una decisión de negocio por la que quieren cambiar de Mailchimp (envío de newsletters) a la competencia. Buena suerte como estés acoplado…
Convergencia con el principio OCP de SOLID
Los principios y buenas prácticas más importantes del desarrollo a menudo convergen, y en este caso, aplazar las decisiones es una manera de seguir el Open Closed Principle de SOLID:
- Cerrado para la modificación: no debemos modificar las reglas de negocio por culpa de factores externos.
- Abierto para la extensión: podemos tener una o varias implementaciones de componentes, y añadir o modificar sin que el funcionamiento del dominio se vea afectado.
Ejemplos prácticos reales
Vamos a ver algunos ejemplos reales, en los que el aplazar decisiones me ha ayudado últimamente:
Sistema de ejecución de tareas programadas
Recientemente en Kirei Studio hemos desarrollado una aplicación que requiere la ejecución de tareas programadas en background. En este caso, es una aplicación web ASP.NET. Para quien no conozca el ecosistema .NET, hay varias librerías para ejecutar tareas en background:
- Quartz.NET
- Hangfire
- FluentScheduler
- QueueBackgroundWorkItem
Necesitábamos analizar las opciones sin parar el desarrollo de la iteración, así que mientras uno estudiaba las opciones, el otro continuaba el desarrollo aplicativo, gracias una sencilla interfaz que definía las necesidades del negocio:
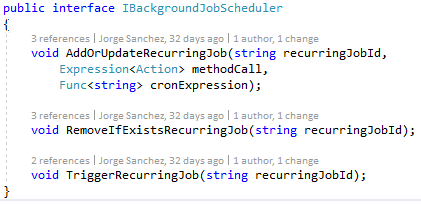
Así que esos casos de uso del aplicativo ya estaban funcionando y con sus tests antes que el componente que se encargaba de la ejecución de tareas estuviera hecho, y una vez hecho, fue tan sencillo como indicarlo en el contenedor de dependencias. Actualmente usamos una clase que se llama HangfireBackgroundJobScheduler, pero gracias a no haber tomado una decisión prematura, nada nos hubiera impedido haber tenido un QuartzBackgroundJobScheduler.
Sistema de persistencia de imágenes
En un ecommerce con varios frontales web, había que desarrollar una especie de CDN sencillo para guardar y obtener las imágenes de los productos. Sin embargo, no teníamos nada claro los requisitos de espacio en disco necesario, ni si había presupuesto para utilizar un sistema externo en la nube como S3. En este caso, lo que acostumbramos a hacer es elegir siempre la opción más simple, que en este caso es simplemente almacenar las imágenes en el disco local del servidor. La interfaz, de nuevo, es muy sencilla:
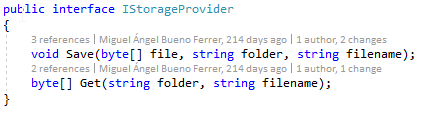
Y la implementación de esta interfaz en la capa de infraestructura es una clase que se llama FileSystemStorageProvider. Si en algún momento surge la necesidad de utilizar almacenamiento en la nube en lugar de en disco local, solo habría que programar un adaptador S3StorageProvider que cumpla la interfaz, y en ningún caso habrá que modificar las reglas de negocio por un detalle de implementación.
Base de datos en aplicación Barfastic
Barfastic es una aplicación Android en Kotlin, con algunas funcionalidades sencillas. Esta aplicación necesitaba un prototipo funcional antes de la primera versión. En principio tenía intención de utilizar Realm en lugar de SQLite, pero como no disponía de tiempo antes de la fecha de presentación del prototipo, se desarrolló con persistencia de datos en ficheros de texto plano, siguiendo esta interfaz:
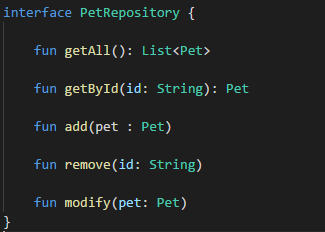
Una vez hecho el prototipo, con todos los casos de uso y entidades de dominio protegidos con sus tests unitarios, pude investigar e implementar con éxito una base de datos con Realm, teniendo que hacer unos pocos tests de integración para garantizar que todo iba bien.
Conclusión
Hemos visto lo beneficioso que es no precipitarse con las decisiones en una arquitectura, de manera tanto directa como indirecta.
Aplazar decisiones de implementación de detalles nos ayuda a tener más información para tomar las decisiones adecuadas cuando llegue el momento, y a no contaminar las reglas de negocio.
Clean Architecture, gracias a su Regla de la Dependencia, nos facilita por diseño el aplazamiento de estas decisiones sobre los detalles.
Así que, cuando tengas la tentación de utilizar la última moda tecnológica, quizá sea conveniente que esperes a que la aplicación en sí misma te indique si eso es lo que realmente necesita. Piénsalo cuando empieces un proyecto que ya desde el primer momento quieras montar con microservicios ;)
Nota: Este texto fue publicado originalmente en el blog de Kirei Studio.